Knowledge Model#
The knowledge model is a tree-like structure of chapters, questions, answers, and other entities that servers as a template for the questionnaire. All the different questions, their possible answers and follow-up questions, metrics and more is defined there.
While all the possibilities are defined in the knowledge model, when researchers use it to create their project, they don’t see everything, but only the top-level questions and more detailed questions are only asked if relevant to their use case.
Knowledge models are created by data stewards in the knowledge model editor.
Knowledge Model Structure#
Knowledge model consists of several entities connected together. You can see how they are connected in the following diagram and read more details about them below.
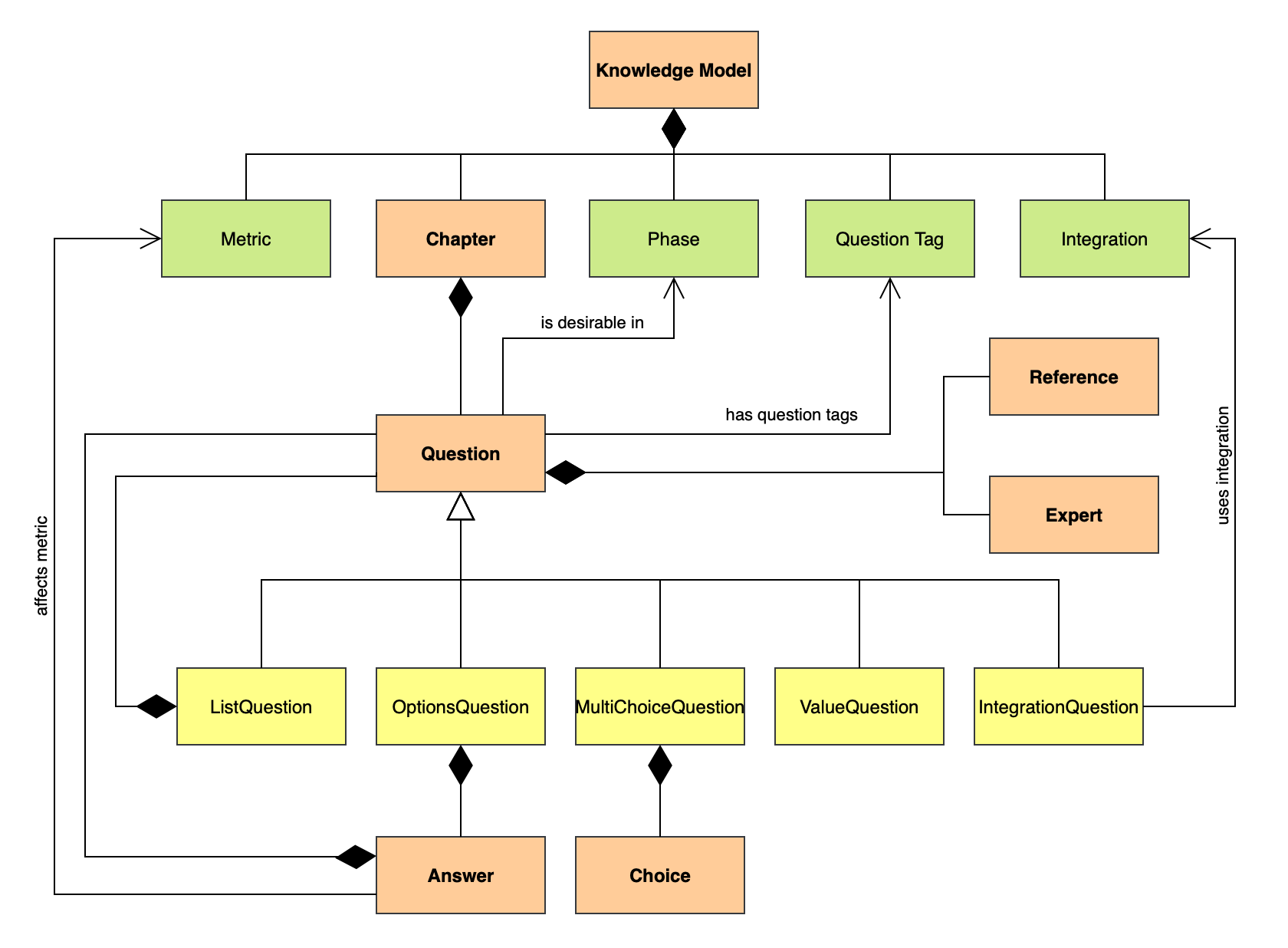
Knowledge model schema#
Knowlege Model#
At the top level, the knowledge model contains chapters, and entities refered to elsewhere from the knowledge model: metrics, phases, question tags, and integrations.
Chapter#
The knowledge model consists of chapters at the top level. Each chapter has a name, a description and a list of questions. Usually, chapters are used to group the questions on the same topic together.
Question#
Questions are used to collect the answers from users. Each question has a title (the actual question), a description, a phase when it becomes desirable, a list of references and experts, and a selection of question tags.
Then there are some additional settings based on the question type.
Options Question#
The options question contains a closed list of answers where users can pick one. Answers can have some follow-up questions that are only presented to the user when they pick the answer. So the options question can be used for questionnaire branching.
List Question#
The list question is used when there are multiple answers and we want to ask more details about those. For example, we can ask about different datasets that will be produced – users will have multiple datasets but we want to ask the same questions for each of those. For that, we configure the item template, which defines the questions for each item.
Value Question#
The value question asks for a single value that users type in. There are many different types of the value question that can be used:
String
Number
Date
Date Time
Time
Text
Email
URL
Color
The input field differs based on the value type (simple input for string, date picker for date, etc.). Some of these have a check whether the entered value is valid (such as valid email or URL) and displays a warning if not.
Integration Question#
The integration question is connected to an external resource where the users can pick the answer from. We need to select an integration that the question uses and sometimes additional properties, based on the integration configuration.
Users can then search the external resource through the questionnaire and choose the answer. The advantage is that the answer is not only the text but also a link or PID of the selected item making it more FAIR.
If the desired answer is not present in the external resource, users can still fill in a text answer themselves.
Multi-Choice Question#
The mutli-choice question has a list of choices. Users can then pick as many of those choices as they wish. There are, however, no follow-up questions available for this question type.
Answer#
An answer is used with options questions. It contains a label which is the answer itself. Then an advice which is visible only if the answer is selected. We can use this when users pick answer that is not great to provide them further guidance on how to improve.
Answers can have follow-up questions that are only visible if the answer is selected. We can use this to ask only relevant questions based on the previous answers.
If tere are some metrics created in the knowledge model, we can configure how each answer affects them. The result for each metric is eventually calculated as a weighted average of all answers affecting that metric. Therefore, we need to configure:
weight [0..1] - how important the answer is (0 = not important at all, 1 = very important)
measure [0..1] - how it affects the metric (0 = bad, 1 = good)
Choice#
A choice is used with mutli-choice questions. It only contains a label which is presented to the user.
Reference#
We can provide some additional references for questions to help users better understand it or learn more details. There are more types of references.
URL Reference#
A URL reference is a simple link to any website. It has URL which is the actual link and a label that describes what the reference is about.
Book Reference#
Warning
Book references are deprecated.
Resource Page Reference#
Warning
Resource page references are not yet implemented.
Expert#
We can provide a contact information to an expert for some questions. An expert has a name and an email. We can use this, for example, if there is an expert for a specific topics in our institution and we want to make it easy to find out in our customized knowledge model.
Metric#
We can define metrics for each knowledge model based on our needs. Each metric has a title, an abbreviation, and a description. Once the metric is defined, we can configure which answers affect it and how.
This can be use, for example, to define the FAIR metrics:
F - Findability
A - Accessibility
I - Interoperability
R - Reusability
And then define which answers affect which FAIR metrics to provide more feedback to the researchers.
Phase#
We can create phases to reflect the workflow. Such as: Before submitting the proposal, Before submitting the DMP, etc. Each phase has a title and a description.
Once we have phases defined, we can assign them to questions to indicate where each question become desirable. The phases implicitly follow the order in which they are in the knowledge model and the question is considered desirable from the defined phase and on. So for example, if a question is desirable in Phase 2, it is implicitly desirable in Phase 3, Phase 4, etc.
Question Tag#
We can define question tags on the knowledge model and then assign them to different questions. This can be used to group together questions on the same topic or for the same purpose.
When researchers create a new project from the knowledge model, they can only choose the question groups they are interested in for their research. So we can use this to create a very rich knolwedge model but researchers will be able to use only the parts relevant to them.
Integration#
Integrations define a connection to an external service or resource where we can get the answers from. They are used with integration questions. For each integration we configure some basic information, such as ID, Name, or Logo URL. Other configuration varies based on the integration type. More information about how to configure integration is available under the integration development.
API Integration#
API integration connects to an external service API to search for the answers. We need to provide some request and response configuration, so DSW can use the API.
Widget Integration#
Widget integration doesn’t use an API but a widget implemented using the DSW Integration Widget SDK. Then we need to configure the widget URL where the widget is deployed.
Annotations#
Annotations are arbitrary key value pairs that can be assigned to any entity in the knowledge model. These can provide some additional information for the document templates.
Knowledge Model Customizations#
A knowledge model doesn’t have to be created from scratch. Instead, it can be created as a customization of an existing knowledge model.
We can choose any existing knowledge model and customize it to our needs. We can add, modify, or remove any entities. If there are newer changes in the parent knowledge model, it is possible to get them into our child knowledge model using the knowledge model migration.